In last week’s article, I showed readers 2 different approaches to plan for how much do you need if you wish to retire at 55 years old so that you will have an income stream till 90 years old.
We acknowledge that at some point, our CPF Life annuity income will be available for us to spend and thus will have to be factored into our planning.
The 2 approaches were:
- Plan to have an income stream that provides $5,000 a month, that is inflation-adjusted outright for the 35-year duration
- Break up into 2 portions. The first portion is to provide predictable income for the first 10 years and the second portion to do the first approach but over a 25-year duration
We deduce that approach 1 is definitely safer but you will need to set aside more money, which may mean you working longer for that security. The second approach is more optimized because we can compute conservatively which portion of your expenses is funded by which portion of your wealth.
The second approach utilizes less money.
The difference between the two approaches narrows if your income needs are higher. This is because if you require such a high income, the proportion of the income from CPF Life is lesser and therefore matters less.
What If We Topped Up CPF Retirement Account to Enhanced Retirement Sum (ERS)?
Those with CPF have the opportunity to top-up their CPF to not just their Full Retirement Sum (FRS) at age 55, but to the Enhanced Retirement Sum (ERS). We can top-up 50% of the FRS to the ERS limit.
For example, suppose you were born in 1960 and your FRS is $161,000 at age 55 in 2015. If you wish to you can top up $161,000/2 = $80,500 more so that you will have a total of $241,500 in your CPF Retirement Account.
A greater amount in our CPF Retirement Account would allow us to have a greater CPF Life Income Stream.
Slight Digress: While we are on the topic of CPF Retirement, do note that if you were born in 1960, if you wish to you can top-up to the prevailing BRS, FRS, ERS so that your income stream is larger.
For example, the current 2020 FRS is $181,000. The couple born in 1960 would just be 60 years old. They can top-up his CPF Retirement Account to $181,000 or $271,500 if they wish to get a greater income stream. There are no CAP there. (The hard FRS sum of $161,000 at 55 years old is there to help you identify the amount in your CPF OA and SA that you can freely take out at 55 years old. I think CPF would welcome you to top-up more into your CPF Retirement Account for a stronger retirement income stream.)
Ok, let us get back to the main topic again.
If we revisit the two approaches again:
- Plan to have an income stream that provides $5,000 a month, that is inflation-adjusted outright for the 35-year duration
- Break up into 2 portions. The first portion is to provide predictable income for the first 10 years and the second portion to do the first approach but over a 25-year duration
The first approach does not benefit much from topping up the ERS. This is because your portfolio at 55 years old have to provide the cash flow to give an inflation-adjusted $5,000 a month income from the very start.
In approach 1, the CPF is a good-to-have.
The second approach may benefit from the CPF Top-up to ERS because the CPF Life income is an integral part of the plan.
I think that having higher CPF Life Annuity may mean we need to set aside less in our cash portfolio because, in Singapore, there are not a lot of financial assets that have almost a 6% initial cash flow yield, backed by a strong entity, that continues as long as you are alive.
Approach 1: Provide a Retirement income stream for 35 years

In the previous post, under approach 1, we estimate based on a 3.25% initial safe withdrawal rate, the retiree needs to set aside $1.85 million.
Their combined CPF Life Income Stream at 65 years old if they choose the CPF Life Basic Plan is $2750 a month assuming they have $181,000 each in their CPF RA at 55 years old.
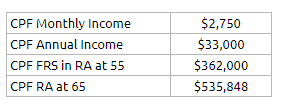
The couple can choose to top-up to ERS in their CPF Retirement Account any time from 55 years old onwards (if I am right). However, the CPF Life calculator is not so flexible to give us an estimated monthly income if you top-up after 55, so I will assume the couple top-up $90,500 each at 55 years old.
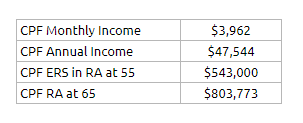
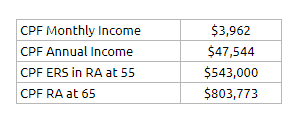
The couple topped up $181,000 more at 55 years old. The CPF Life Calculator estimates that based on this additional funding, and if CPF Life Basic Plan was chosen, the income would be bumped up by $1,212 a month.
In approach 1, this bump up does not matter so much because the couple could not spend the income until they get it at 65 years old. By spending $181,000 more, it does make their overall plan safer.
In total, the couple would need $1.85 mil + $181,000 = $2.03 million based on approach 1. Honestly, I cannot bring myself to tell people to fork out an additional $181,000 just to make their plan safer.
I am just not so sure if it is worth it.
Approach 2: A Cash Portion for first 10 years Plus an Income Stream from Portfolio for 25 years
My opinion is that topping-up your CPF Retirement Account to the ERS may matter more to Approach 2.
Let us take a look at the annual expenses of the couple that they need an income to cover, after factoring this new CPF Life Income of $3,962 a month versus $2,750 a month previously:
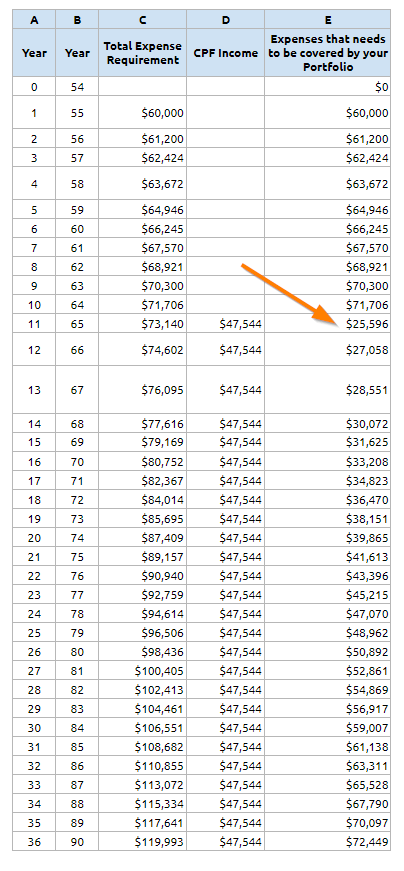
Wow ok.
At 65 years old, our cash portfolio will just have to cover $25,596 a year in expenses, compared to $40,140 a year previously.
We can determine how much capital we need at 65 years old to fund this $25,596 a year, by going back to our safe initial withdrawal rate table:
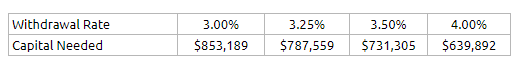
In the last article, for approach 2, I used a 4% initial withdrawal rate so in this article I will stick with this.
This couple will need $639,892. (To be more safe, you could choose to accumulate $731,305 at a 3.5% initial withdrawal rate as well).
For comparison, here is how much capital you need based on the last article, if the annual income requirement is $40,140:

The capital difference between having a higher CPF Life and not is about $400,000! What this emphasizes more is that if your expenses are higher, your capital needs are higher.
How much capital do we need at 55 years old so that we can have $639,892 at 65 years old?
We need to see how much in our cash portfolio we need at 55 years to grow it to $639,892 at age 65.
Assuming a rate of return of 4.5% a year, at 55 years old, the couple will need $639,892/(1.045)^10 = $412,044. (If 3.5% initial withdrawal rate, then you will need $731,305/(1.045)^10 = $470,907)
Remember, we have to factor in a capital of $600,000 to fund 10 years of $60,000 a year spending before the CPF Life annuity income comes online.
Thus, the total capital needed equals to:
- First 10 years capital: $600,000
- Cash portfolio at 55 years old: $412,044
- Capital to top-up CPF RA to ERS at 55 years old: $181,000
The total comes up to $1.19 million.
Compare this to $1.24 million in my previous article.
Not a lot of difference apparently!
Ok, this is a surprise. I thought the difference by channeling more to CPF life might be greater. Turns out not a lot of difference!
Comparing the Two Retirement Income Planning Approaches
Again, if we compare the two approaches it will be $1.85 million versus $1.19 million.
Approach 2 requires less capital at age 55. If you are cash-strapped this one will be more worth it.
I cannot bring myself to include the CPF top-up for approach 1 since it didn’t really help the approach concept-wise.
What if Your Retirement Income Requirement is Higher?
In my previous article, I tried to work out the scenario if the couple needs $8,000 a month in the first year at 55 years old instead of $5,000 a month.
I shall not bore you with the calculations, so here is the total capital needed for Approach 2 if its $8,000 a month:
- First 10 years capital: $960,000
- Cash portfolio at 55 years old: $1,353,977
- Capital to top-up CPF RA to ERS at 55 years old: $181,000
The total comes up to $2.49 million. In the previous article, if we did not top-up to ERS, we would need $2.31 million.
Topping up to ERS seem to not work so well as the retirement income requirement goes up.
I was not expecting this. I think I better compute the difference between topping-up your CPF Retirement Account to ERS versus not topping up for different income requirements:

As you go up the income, the difference is almost the same. However, the same $53,132 in lump sum capital does not make much difference when your income requirement and subsequently capital gets rather large.
That said, suppose your additional income needs are $500 to $1000 a month. If you choose to top-up to ERS, your situation is better off than investing outside in terms of percentage (for example the capital you need is 10% less which is significant).
We can judge how significant is a $53k difference. For some couples, saving $53,132 more can be really tough thus topping-up ERS makes more sense.
Summary
It feels to me that we can conclude topping up versus not topping up your CPF Retirement account to Enhanced Retirement Sum does not make so much difference.
However, I would like to point out the difference:
- CPF Life is an annuity. It is backed by a government entity and is designed to hedge your longevity risk (outliving your income)
- Your cash portfolio is a probability-based income stream. While you can control how much income as a percentage of total capital you wish to spend a year, the robustness of the income stream depends on the markets giving you a set of returns similar to the past
These 2 features mean there is a role for both in your portfolio. For some retirees, they would rather base their income stream on the safety of a government-sponsored annuity scheme.
However, if your income requirement is so large, then you best get comfortable investing in an equity and bond portfolio because you are not going to find an instrument that gives you such a good annuity income yield.
CPF is a scheme that sought to help the second quartile of Singaporeans. If your needs are greater than that, then you need greater solutions.
I invested in a diversified portfolio of exchange-traded funds (ETF) and stocks listed in the US, Hong Kong and London.
My preferred broker to trade and custodize my investments is Interactive Brokers. Interactive Brokers allow you to trade in the US, UK, Europe, Singapore, Hong Kong and many other markets. Options as well. There are no minimum monthly charges, very low forex fees for currency exchange, very low commissions for various markets.
To find out more visit Interactive Brokers today.
Join the Investment Moats Telegram channel here. I will share the materials, research, investment data, deals that I come across that enable me to run Investment Moats.


Do Like Me on Facebook. I share some tidbits that are not on the blog post there often. You can also choose to subscribe to my content via the email below.
I break down my resources according to these topics:
- Building Your Wealth Foundation – If you know and apply these simple financial concepts, your long term wealth should be pretty well managed. Find out what they are
- Active Investing – For active stock investors. My deeper thoughts from my stock investing experience
- Learning about REITs – My Free “Course” on REIT Investing for Beginners and Seasoned Investors
- Dividend Stock Tracker – Track all the common 4-10% yielding dividend stocks in SG
- Free Stock Portfolio Tracking Google Sheets that many love
- Retirement Planning, Financial Independence and Spending down money – My deep dive into how much you need to achieve these, and the different ways you can be financially free
- Providend – Where I used to work doing research. Fee-Only Advisory. No Commissions. Financial Independence Advisers and Retirement Specialists. No charge for the first meeting to understand how it works
- Havend – Where I currently work. We wish to deliver commission-based insurance advice in a better way.
Kyith is the Owner and Sole Writer behind Investment Moats. Readers tune in to Investment Moats to learn and build stronger, firmer wealth foundations, how to have a Passive investment strategy, know more about investing in REITs and the nuts and bolts of Active Investing.
Readers also follow Kyith to learn how to plan well for Financial Security and Financial Independence.
Kyith worked as an IT operations engineer from 2004 to 2019. Currently, he works as a Senior Solutions Specialist in Insurance Start-up Havend. All opinions on Investment Moats are his own and does not represent the views of Providend.
You can view Kyith's current portfolio here, which uses his Free Google Stock Portfolio Tracker.
His investment broker of choice is Interactive Brokers, which allows him to invest in securities from different exchanges all over the world, at very low commission rates, without custodian fees, near spot currency rates.
You can read more about Kyith here.
Alan
Sunday 28th of June 2020
Hello, I’m 47 now and already have 165K in OA/SA combined. As of now, the enhanced retirement level is 271K, which is another 100K away. Assuming I have 100K tomorrow, does it make sense to reach the enhanced sum straight away, so I get a much bigger payout when I am 65 (yeah, I do understand the goal post for enhanced retirement sum keeps going up yearly). But if I reach the limit current tormorrow, the 4% interest rate will take care of the shifting goal post a little bit and also I will be continuing to contribute monthly as well. Several questions here - is this allowed? Is it a good move! Is it worth it! Is it possible to have more than.271K? The CPF retirement amount calculator says you can input a number only up to 500K. Any thoughts on what’s the best course?
Kyith
Wednesday 1st of July 2020
HI Alan,
The short answer is that it is allowed. As the ERS threshold shift up, you can put more money in. However, at some point, you got to ask whether you should be putting more money in or start taking money out. The system is there to give you a reliable income but you do not want to end up trying to maximizing it and spend only 2 years of it and then you cannot spend anymore.
The ERS threshold takes into consideration only the principal. This means that currently the 4-5% interest earned in RA is not factored into the ERS threshold computation.
Lastly, I hope more folks don't get to a situation where they rely solely on the CPF. It would be better to have something that at least gives them some inflation adjustments.
Kay
Monday 27th of January 2020
15 years into retirement and at 70, how will this aged couple will be able to continue generating 4.5% pa return that will likely needs to be capital protected. Add another 10 years, at 80, how could the couple cope?
I think there is probably great interests out there for near retirement people who are not investment savvy to understand how this can be done?
Oken
Wednesday 5th of February 2020
Are their kids investment savvy? If not, I would think the best way is to dump whatever they can afford into CPF life and let it manage on your behalf.
Sure, they can learn to invest, but as they age, would they be mentally able to continue doing so? If they cannot, can their children take over? If they have more than one kid, who will take over and will this arrangement lead to conflicts down the line?
Mathematically, perhaps some investment portfolio might work better. But is it as convenient to operationalize?
Kyith
Tuesday 28th of January 2020
Hi Kay,
They could put their money in a balanced portfolio of 40% equity 60% bonds, 50% equity 50% bonds, 60% equity 40% bonds to have a chance to generate that return. 25 years is still a pretty long time frame. The research have shown that if you do not have adequate equity allocation, your portfolio stands a lower chance it will last for 25 years.
The problem for most people... is that they need to understand general equity and bonds relationship over time better. I tried writing some of it but i wonder how many feel a 60/40 portfolio is safe enough.
Best Regards,
Kyith
Oken
Monday 27th of January 2020
I understand. And yes, I was referring to the differential between FRS and ERS.
I just didn't think it was fair to describe CPF life as 'not much difference'. I would find it difficult to find instances where one choose NOT to top up to ERS if one was financially able to.
I don't think there are any other investments which would payout so much at such a low level of risk. My general assumption is that everyone should pump CPF life for as much as they can. Perhaps it would be useful to explore to what extent we should leverage CPF life and under what circumstances it would be unwise to do so...
Kyith
Tuesday 28th of January 2020
Hi Oken, thanks for sharing your thoughts. I think i laid out the case where i thought it will make a different and sort of came to a conclusion it might make less of a difference. The ERS is good for those people who have more but really not much more, and their expenses are rather in control. That is why I say "might". I will lean towards not make so much of a difference because most readers would be expecting to spend $4000 to $9000 a month. In this region, ERS might not make much of a difference at all.
Sinkie
Monday 27th of January 2020
CPF is geared towards low & lower middle-income, provided they do their part to hit at least the BRS.
This is why the extra 1% and 2% interest is only applied to the first $60K. These "socialised subsidies" won't mean much to those with million-dollar CPF accounts (or even $300K accounts).
If you're "rich", you're expected to be able to take care of your own finances.
@Oken,
You won't be able to double your annuity by going from FRS to ERS, since ERS is just 50% more than FRS.
In fact you will get slightly less than 50% more from ERS than FRS. This is becoz, as I have explained above, the returns of CPF Life are weighted more to the first $60K.
You can confirm this by playing around with the CPF Life calculator: Annuity amount from FRS is less than 2X from BRS. And the amount from ERS is less than 1.5X from FRS.
Oken
Sunday 26th of January 2020
For a single person to have a annual income of $6k according to the 4% rule, he needs a lump sum of $150k. For a Singaporean to get an additional $6k per year (FRS to ERS), he needs to have a lump sum of $90,500.
How is this not significant or worth it?
Kyith
Sunday 26th of January 2020
Hi Oken, I think i need to understand your question more clearly. If a person who needs $6k a year, he do not need ERS. FRS or BRS will do.
Rayson Teng
Sunday 26th of January 2020
Show me how to get 6k ....